Práctica 2. Descripción de variables
Índice
Objetivo de la práctica
Esta segunda práctica tiene por objetivo repasar algunos conceptos básicos de los cursos anteriores de Estadística Descriptiva y Estadística Correlacional. Asume como base el desarrollo de la Práctica 1, a la cual se hará referencia permanente.
En la Práctica 1 se desarrolló un código de preparación de datos que generó una base de datos procesada para el análisis. En esta Práctica 2 comenzamos con el segundo momento de procesamiento de datos, que es el análisis propiamente tal. El análisis se divide en descripción de variables y contraste de hipótesis. En esta práctica nos enfocaremos en la primera fase, que llega hasta el punto 3 del código de análisis:
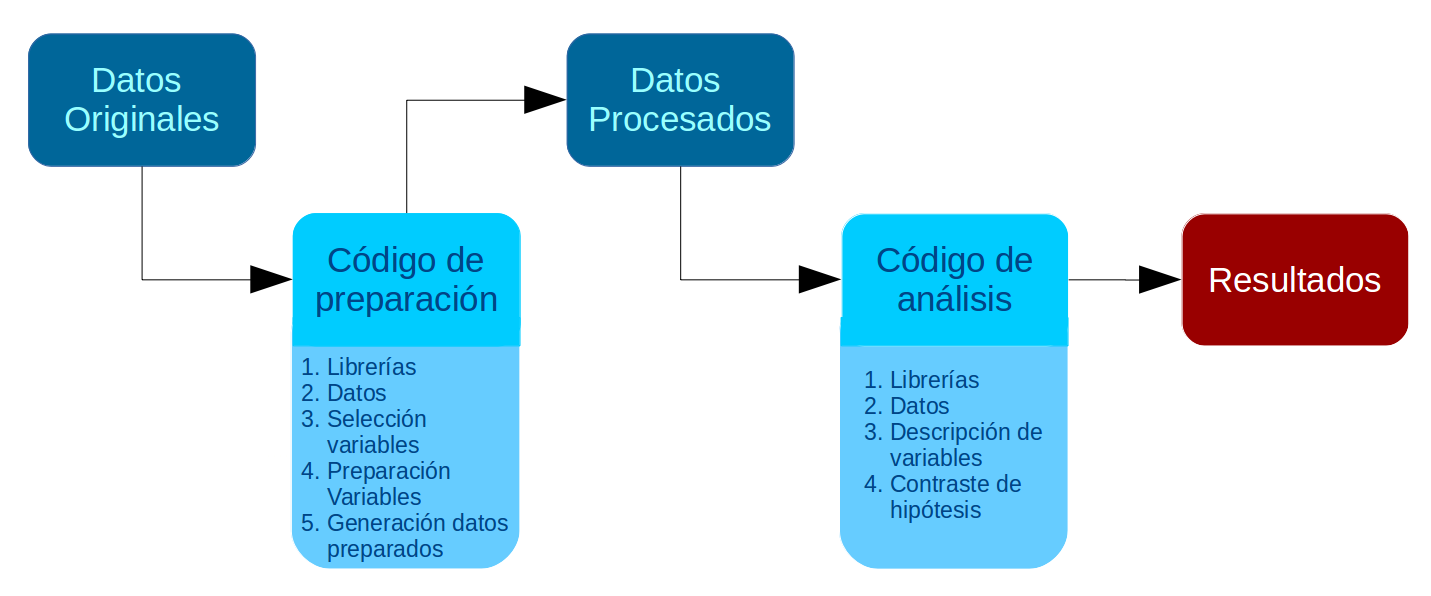
Al igual que el Código de Preparación, el Código de Análisis posee una estructura definida. En este caso son 4 partes, donde las primeras son similares al código de preparación:
- Identificación y descripción general: Título, autor(es), fecha, información breve sobre el contenido del documento
- Librerías principales (de R) a utilizar en el análisis
- Datos (que provienen de los preparados en la fase anterior)
- Descripción de variables
- Tabla general de variables para la sección metodológica del reporte
- Exploración descriptiva de relaciones entre variables
- Contraste de hipótesis / inferencia estadística según la técnica que corresponda
Al final de esta práctica la idea es que cada un_ pueda avanzar hasta el punto 3 del Código de Análisis. El punto 4 (contraste de hipótesis) se desarrollará más adelante en este curso con énfasis en la técnica de regresión.
Código de análisis
1. Librerías
La explicación de esta parte del código se encuentra en la sección correspondiente de la práctica 1.pacman::p_load
2. Cargar base de datos
Vamos a cargar la base de datos ELSOC_ess_merit2016.Rproc_elsoc, que generamos durante la práctica 1. Se puede llamar desde el directorio en que la guardaron dando la ruta completa, o también para esta práctica la podemos llamar directamente desde nuestro sitio web:
- Exploración inicial general de la base de datos
## [1] "mesfuerzo" "mtalento" "ess" "edcine" "sexo" "edad"
## [7] "pmerit"## [1] 2927 7En el caso de esta base, 2927 casos y 7 variables
Recordando el contenido de cada variable preparada en la práctica 1:
[
merit] = Indice promedio de percepción de meritocracia.[
ess] = Estatus Social Subjetivo: Donde se ubicaria ud. en la sociedad chilena" (0 = el nivel mas bajo; 10 = el nivel mas alto)[
edcine] = Nivel educacional(1 = Primaria incompleta menos, 2 = Primaria y secundaria baja, 3 = Secundaria alta, 4 = Terciaria ciclo corto, 5 = Terciaria y Postgrado)[
sexo] = Sexo (O = Hombre; 1 = Mujer)[
edad] = ¿Cuáles su edad? (años cumplidos)
3. Descripción de variables
Los resultados referidos a descripción de variables se presentan en dos momentos del reporte de investigación:
en la sección de metodología, cuando se presentan las variables del estudio en una tabla descriptiva de variables.
en la sección de análisis, que en general comienza con una exploración de asociaciones entre variables, también conocido como análisis descriptivo.
3.1 Tabla descriptiva de variables para sección metodológica
A continuación se presentan dos opciones de generar esta tabla descriptiva de variables con distintas librerías de R.
a. Tabla descriptiva con stargazerstargazer
La función stargazer (de la librería del mismo nombre) permitirá mostrar los principales estadísticos descriptivos univariados de las variables: medidas de tendencia central (media), de dispersión (desviación estándar) y posición (mínimo, máximo, percentiles).
##
## ==============================================================
## Statistic N Mean St. Dev. Min Pctl(25) Pctl(75) Max
## --------------------------------------------------------------
## mesfuerzo 2,909 2.573 1.047 1.000 2.000 3.000 5.000
## mtalento 2,907 2.739 1.060 1.000 2.000 4.000 5.000
## ess 2,915 4.330 1.567 0.000 3.000 5.000 10.000
## edcine 2,925 3.184 1.207 1.000 3.000 4.000 5.000
## sexo 2,927 0.603 0.489 0 0 1 1
## edad 2,927 46.091 15.287 18 33 58 88
## pmerit 2,898 2.654 0.969 1.000 2.000 3.500 5.000
## --------------------------------------------------------------Algunas observaciones sobre esta tabla:
La opción
type="text"permite que podamos ver los resultados directamente en la consola, de manera bastante rudimentaria. Con otras opciones que veremos más adelante se puede estilizar para su publicación.Una distinción relevante a considerar cuando se describen variables es si estas son categóricas o continuas. La definición de si una variables es tratada como categórica o continua es algo que hace el/la autor/a del reporte, sin embargo hay variables nominales como sexo que claramente corresponden a categóricas, y por lo tanto no corresponde hacer un promedio entre ambas. Sin embargo, como esta variable está codificada 0 (hombre) y 1 (mujer), en este caso lo que indica el valor de la columna promedio (Mean=0.60) es la proporción de mujeres vs hombres. En otras palabras, hay un 60% de mujeres y 40% de hombres en la muestra.
b. Tablas descriptivas con descr, librería sjmiscsjmisc::descr
La opción básica de descr es la siguiente:
##
## ## Basic descriptive statistics
##
## var type label n NA.prc mean sd se md
## mesfuerzo numeric Recompensa: esfuerzo 2909 0.61 2.57 1.05 0.02 2.0
## mtalento numeric Recompensa: talento 2907 0.68 2.74 1.06 0.02 3.0
## ess numeric Estatus Social Subjetivo 2915 0.41 4.33 1.57 0.03 5.0
## edcine numeric Educación 2925 0.07 3.18 1.21 0.02 3.0
## sexo numeric Sexo 2927 0.00 0.60 0.49 0.01 1.0
## edad numeric Edad 2927 0.00 46.09 15.29 0.28 46.0
## pmerit numeric Meritocracia promedio 2898 0.99 2.65 0.97 0.02 2.5
## trimmed range skew
## 2.56 4 (1-5) 0.42
## 2.76 4 (1-5) 0.18
## 4.36 10 (0-10) -0.01
## 3.23 4 (1-5) -0.15
## 0.63 1 (0-1) -0.42
## 45.90 70 (18-88) 0.07
## 2.66 4 (1-5) 0.26En este caso utilizamos la forma librería::función (sjmisc::descr), ya que la función descr también existe en otras librerías y así nos aseguramos que la función utilizada es de esa librería específica.
Seleccionamos algunas columnas específicas con información más relevante con la opción show. Además, agregamos la función kable para obtener una tabla que luego sea fácilmente publicable en distintos formatos (a profundizar en una práctica posterior):
sjmisc::descr(proc_elsoc,
show = c("label","range", "mean", "sd", "NA.prc", "n"))%>%
kable(.,"markdown")| var | label | n | NA.prc | mean | sd | range | |
|---|---|---|---|---|---|---|---|
| 4 | mesfuerzo | Recompensa: esfuerzo | 2909 | 0.6149641 | 2.5727054 | 1.0466874 | 4 (1-5) |
| 5 | mtalento | Recompensa: talento | 2907 | 0.6832935 | 2.7389061 | 1.0596182 | 4 (1-5) |
| 3 | ess | Estatus Social Subjetivo | 2915 | 0.4099761 | 4.3300172 | 1.5666965 | 10 (0-10) |
| 2 | edcine | Educación | 2925 | 0.0683293 | 3.1839316 | 1.2066058 | 4 (1-5) |
| 7 | sexo | Sexo | 2927 | 0.0000000 | 0.6026648 | 0.4894300 | 1 (0-1) |
| 1 | edad | Edad | 2927 | 0.0000000 | 46.0908780 | 15.2867983 | 70 (18-88) |
| 6 | pmerit | Meritocracia promedio | 2898 | 0.9907755 | 2.6538992 | 0.9694792 | 4 (1-5) |
c. Tabla descriptiva con summarytools::dfSummarysummarytools::dfSummary
Esta tercera opción nos ofrece una tabla aún más detallada, con gráficos para cada variable, las frecuencias para cada valor, y las etiquetas de las variables, por lo que es muy recomendable.
Se específica de la siguiente manera:
## ### Data Frame Summary
## #### proc_elsoc
## **Dimensions:** 2927 x 7
## **Duplicates:** 396
##
## ----------------------------------------------------------------------------------------------------------------------------------------
## No Variable Label Stats / Values Freqs (% of Valid) Graph Valid Missing
## ---- ------------ -------------------------- -------------------------- ---------------------- -------------------- ---------- ---------
## 1 mesfuerzo\ Recompensa: esfuerzo Mean (sd) : 2.6 (1)\ 1 : 357 (12.3%)\ II \ 2909\ 18\
## [numeric] min < med < max:\ 2 : 1331 (45.8%)\ IIIIIIIII \ (99.39%) (0.61%)
## 1 < 2 < 5\ 3 : 497 (17.1%)\ III \
## IQR (CV) : 1 (0.4) 4 : 646 (22.2%)\ IIII \
## 5 : 78 ( 2.7%)
##
## 2 mtalento\ Recompensa: talento Mean (sd) : 2.7 (1.1)\ 1 : 288 ( 9.9%)\ I \ 2907\ 20\
## [numeric] min < med < max:\ 2 : 1163 (40.0%)\ IIIIIIII \ (99.32%) (0.68%)
## 1 < 3 < 5\ 3 : 559 (19.2%)\ III \
## IQR (CV) : 2 (0.4) 4 : 814 (28.0%)\ IIIII \
## 5 : 83 ( 2.9%)
##
## 3 ess\ Estatus Social Subjetivo Mean (sd) : 4.3 (1.6)\ 11 distinct values \ 2915\ 12\
## [numeric] min < med < max:\ \ \ \ \ \ \ \ \ :\ (99.59%) (0.41%)
## 0 < 5 < 10\ \ \ \ \ \ \ . :\
## IQR (CV) : 2 (0.4) \ \ \ \ . : :\
## \ \ \ \ : : : .\
## . : : : : : .
##
## 4 edcine\ Educación Mean (sd) : 3.2 (1.2)\ 1 : 359 (12.3%)\ II \ 2925\ 2\
## [numeric] min < med < max:\ 2 : 297 (10.2%)\ II \ (99.93%) (0.07%)
## 1 < 3 < 5\ 3 : 1251 (42.8%)\ IIIIIIII \
## IQR (CV) : 1 (0.4) 4 : 483 (16.5%)\ III \
## 5 : 535 (18.3%) III
##
## 5 sexo\ Sexo Min : 0\ 0 : 1163 (39.7%)\ IIIIIII \ 2927\ 0\
## [numeric] Mean : 0.6\ 1 : 1764 (60.3%) IIIIIIIIIIII (100%) (0%)
## Max : 1
##
## 6 edad\ Edad Mean (sd) : 46.1 (15.3)\ 63 distinct values \ 2927\ 0\
## [numeric] min < med < max:\ \ \ . . . : :\ (100%) (0%)
## 18 < 46 < 88\ . : : : : : .\
## IQR (CV) : 25 (0.3) : : : : : : : :\
## : : : : : : : :\
## : : : : : : : : .
##
## 7 pmerit\ Meritocracia promedio Mean (sd) : 2.7 (1)\ 1.00 : 243 ( 8.4%)\ I \ 2898\ 29\
## [numeric] min < med < max:\ 1.50 : 79 ( 2.7%)\ \ (99.01%) (0.99%)
## 1 < 2.5 < 5\ 2.00 : 1041 (35.9%)\ IIIIIII \
## IQR (CV) : 1.5 (0.4) 2.50 : 222 ( 7.7%)\ I \
## 3.00 : 536 (18.5%)\ III \
## 3.50 : 169 ( 5.8%)\ I \
## 4.00 : 528 (18.2%)\ III \
## 4.50 : 38 ( 1.3%)\ \
## 5.00 : 42 ( 1.5%)
## ----------------------------------------------------------------------------------------------------------------------------------------Es muy ancha para visualizar bien en la consola de R, pero en su versión más definitiva de publicación se verá así:
| No | Variable | Label | Stats / Values | Freqs (% of Valid) | Graph | Valid | Missing | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | mesfuerzo [numeric] | Recompensa: esfuerzo | Mean (sd) : 2.6 (1) min < med < max: 1 < 2 < 5 IQR (CV) : 1 (0.4) |
|
 |
2909 (99.39%) | 18 (0.61%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 2 | mtalento [numeric] | Recompensa: talento | Mean (sd) : 2.7 (1.1) min < med < max: 1 < 3 < 5 IQR (CV) : 2 (0.4) |
|
 |
2907 (99.32%) | 20 (0.68%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 3 | ess [numeric] | Estatus Social Subjetivo | Mean (sd) : 4.3 (1.6) min < med < max: 0 < 5 < 10 IQR (CV) : 2 (0.4) | 11 distinct values |  |
2915 (99.59%) | 12 (0.41%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 4 | edcine [numeric] | Educación | Mean (sd) : 3.2 (1.2) min < med < max: 1 < 3 < 5 IQR (CV) : 1 (0.4) |
|
 |
2925 (99.93%) | 2 (0.07%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 5 | sexo [numeric] | Sexo | Min : 0 Mean : 0.6 Max : 1 |
|
 |
2927 (100%) | 0 (0%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 6 | edad [numeric] | Edad | Mean (sd) : 46.1 (15.3) min < med < max: 18 < 46 < 88 IQR (CV) : 25 (0.3) | 63 distinct values |  |
2927 (100%) | 0 (0%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 7 | pmerit [numeric] | Meritocracia promedio | Mean (sd) : 2.7 (1) min < med < max: 1 < 2.5 < 5 IQR (CV) : 1.5 (0.4) |
|
 |
2898 (99.01%) | 29 (0.99%) |
Generated by summarytools 0.9.6 (R version 3.6.0)
2020-04-23
Nota sobre casos perdidos (NAs) na.omit(data)
Hasta ahora hemos mantenido los casos perdidos en la base de datos, ya que son importantes de reportar en la tabla general de variables. Sin embargo, de aquí en adelante se recomienda trabajar solo con casos completos, es decir, sacar los casos perdidos. El quitar los casos perdidos de una base de datos es muy simple con la función na.omit, pero para tomar precauciones y asegurarse que funciona se recomienda el siguiente procedimiento:
- respaldar la base de datos original en el espacio de trabajo (por si queremos en adelante realizar algún análisis referido a casos perdidos), la dejaremos con el nombre proc_elsoc_original.
- contamos el número de casos con el comando
dim - contamos el número de casos perdidos con
sum(is.na(proc_elsoc)) - borramos los casos perdidos con
proc_elsoc <-na.omit(proc_elsoc) - contamos nuevamente con
dimpara asegurarnos que se borraron - y por temas de funcionamiento de R, al realizar la operación de sacar casos perdidos, se borra toda la información de las etiquetas (labels), así que las recuperamos de la base original con el comando
copy_labels, de la libreríasjlabelled.
## [1] 2927 7## [1] 81## [1] 2887 73.2 Exploración de asociación entre variables
Dado que las hipótesis de investigación corresponden a asociación entre variables, antes de realizar el contraste de hipótesis se suele presentar un análisis descriptivio que explora las asociaciones entre variables.
La forma de explorar las asociaciones entre variables dependen de la naturaleza de las variables que se asocian:
- Variables categóricas: tabla de contingencia
- Variable categórica y continua: tabla de promedios por cada categoría
- Variables continuas: correlaciones.
En esta sección también es muy relevante la visualización de datos mediante gráficos, por lo que incluiremos algunos.
El uso tanto de tablas como de gráficos en el reporte queda a discreción del/a autor/a. La pregunta que orienta esta decisión es: ¿Me permite enriquecer la discusión de los resultados en relación a las hipótesis planteadas?
Tablas de contingencia para variables categóricas
Para tablas de contingencia categóricas utilizaremos la función sjt.xtab, de la librería sjPlot. Veamos primero una especificación simple: sjPlot::sjt.xtab
| Educación | Sexo | Total | |
|---|---|---|---|
| Hombre | Mujer | ||
|
Primaria incompleta menos |
102 | 247 | 349 |
|
Primaria y secundaria baja |
105 | 186 | 291 |
| Secundaria alta | 511 | 727 | 1238 |
|
Terciaria ciclo corto |
186 | 292 | 478 |
|
Terciaria y Postgrado |
245 | 286 | 531 |
| Total | 1149 | 1738 | 2887 | χ2=28.154 · df=4 · Cramer’s V=0.099 · p=0.000 |
Al ejecutar el comando, el resultado aparece automáticamente en el visor de RStudio. A esta tabla podemos también agregar porcentajes de filas y/o columnas, según sea lo más relevante analizar. En general se recomienda agregar solo un porcentaje, de otra manera la tabla se satura de información. Además, vamos a quitar el pie de la tabla (conviene dejarlo solo si hay hipótesis asociadas al cruce simple entre las dos variables).
| Educación | Sexo | Total | |
|---|---|---|---|
| Hombre | Mujer | ||
|
Primaria incompleta menos |
102 8.9 % |
247 14.2 % |
349 12.1 % |
|
Primaria y secundaria baja |
105 9.1 % |
186 10.7 % |
291 10.1 % |
| Secundaria alta |
511 44.5 % |
727 41.8 % |
1238 42.9 % |
|
Terciaria ciclo corto |
186 16.2 % |
292 16.8 % |
478 16.6 % |
|
Terciaria y Postgrado |
245 21.3 % |
286 16.5 % |
531 18.4 % |
| Total |
1149 100 % |
1738 100 % |
2887 100 % |
Tablas de promedio de variable continua por una categóricas
En ejemplo vamos a explorar datos de nuestra variable de percepción de meritocracia pmerit por los niveles educacionales edcine.
Una forma rápida de explorar esto es mediante la función tapply, que nos entrega de manera simple el promedio de una variable por otra:
## 1 2 3 4 5
## 2.968481 2.697595 2.662763 2.479079 2.559322Aquí vemos en promedio de pmerit para cada uno de los 5 niveles de la variable educación edcine. Si se estima conveniente este tipo de cruces se puede representar también en una tabla con más opciones de información y también de publicación. Para esto utilizaremos una función algo más compleja de la librería dplyr.dplyr Esta librería permite aplicar una serie de funciones concatenadas y enlazadas mediante el operador %>%. El sentido de cada función aparece comentado abajo:
proc_elsoc %>% # se especifica la base de datos
select(pmerit,edcine) %>% # se seleccionan las variables
dplyr::group_by(Educación=sjlabelled::as_label(edcine)) %>% # se agrupan por la variable categórica y se usan sus etiquetas con as_label
dplyr::summarise(Obs.=n(),Promedio=mean(pmerit),SD=sd(pmerit)) %>% # se agregan las operaciones a presentar en la tabla
kable(, format = "markdown") # se genera la tabla| Educación | Obs. | Promedio | SD |
|---|---|---|---|
| Primaria incompleta menos | 349 | 2.968481 | 0.9828315 |
| Primaria y secundaria baja | 291 | 2.697595 | 1.0041093 |
| Secundaria alta | 1238 | 2.662762 | 0.9685655 |
| Terciaria ciclo corto | 478 | 2.479080 | 0.9431323 |
| Terciaria y Postgrado | 531 | 2.559322 | 0.9223446 |
Esta asocación también se puede representar de manera más simple con un gráfico, en este caso de cajas o boxplot mediante la función plot_grpfrq de sjPlot:sjPlot::plot_grpfrq

Correlaciones (variables continuas)
Algunas notas sobre correlación:
El coeficiente de correlación mide la fuerza de la relación lineal entre dos variable continuas. Esta puede ser:
- positiva: a medida que aumenta una, aumenta la otra (ej: estatura y edad)
- negativa: a medida que una aumenta, disminuye la otra (ej: tiempo dedicado al estudio y probabilidad de reprobar)
- neutra: no hay asociación entre variables.
El rango de variación del coeficiente de correlación va desde -1 (correlación negativa perfecta) y 1 (correlación positiva perfecta).
Existen diferentes formas de cálculo del coeficiente de correlación (Spearman, Kendall, Pearson).
En el coeficiente de correlación se analiza tanto su tamaño como su significación estadística.
En lo que sigue nos concentraremos en el coeficiente de correlación más utilizado que es el de Pearson, que se aplica cuando las variables son de naturaleza continua.
Tablas/matrices de correlación
Las correlaciones entre variables se presentan en general en modo de matrices, es decir, las variables se presentan en las filas y las columnas y en las celdas donde se cruzan los pares de variables se muestra su coeficiente de correlación.
En su forma simple en R se aplica la función cor a lacor base de datos, y la guardamos en un objeto que le damos el nombre M para futuras operaciones:
## mesfuerzo mtalento ess edcine sexo
## mesfuerzo 1.000000000 0.69768811 -0.004312135 -0.12167659 -0.04480502
## mtalento 0.697688106 1.00000000 0.018447696 -0.10582754 -0.03759340
## ess -0.004312135 0.01844770 1.000000000 0.28959248 -0.03745546
## edcine -0.121676591 -0.10582754 0.289592479 1.00000000 -0.08682644
## sexo -0.044805024 -0.03759340 -0.037455462 -0.08682644 1.00000000
## edad 0.096495547 0.07383771 -0.066031873 -0.37660283 0.06121699
## pmerit 0.920404032 0.92224547 0.007740598 -0.12341680 -0.04469515
## edad pmerit
## mesfuerzo 0.09649555 0.920404032
## mtalento 0.07383771 0.922245465
## ess -0.06603187 0.007740598
## edcine -0.37660283 -0.123416804
## sexo 0.06121699 -0.044695146
## edad 1.00000000 0.092369792
## pmerit 0.09236979 1.000000000Este es el reporte simple, pero no muy amigable a la vista. Para una versión más amable utilizamos la función sjt.corrsjPlot::sjt.corr:NOTA: sjPlot actualizó su librería a fines de Mayo (versión 2.8.4); para quienes hayan actualizado a esta versión, la función para tabla de correlaciones ahora es tab_corr
| Recompensa: esfuerzo | Recompensa: talento | Estatus Social Subjetivo | Educación | Sexo | Edad | Meritocracia promedio | |
|---|---|---|---|---|---|---|---|
| Recompensa: esfuerzo | 0.698*** | -0.004 | -0.122*** | -0.045* | 0.096*** | 0.920*** | |
| Recompensa: talento | 0.698*** | 0.018 | -0.106*** | -0.038* | 0.074*** | 0.922*** | |
| Estatus Social Subjetivo | -0.004 | 0.018 | 0.290*** | -0.037* | -0.066*** | 0.008 | |
| Educación | -0.122*** | -0.106*** | 0.290*** | -0.087*** | -0.377*** | -0.123*** | |
| Sexo | -0.045* | -0.038* | -0.037* | -0.087*** | 0.061** | -0.045* | |
| Edad | 0.096*** | 0.074*** | -0.066*** | -0.377*** | 0.061** | 0.092*** | |
| Meritocracia promedio | 0.920*** | 0.922*** | 0.008 | -0.123*** | -0.045* | 0.092*** | |
| Computed correlation used pearson-method with listwise-deletion. | |||||||
Con esta mejor visualización, algunas observaciones sobre la matriz de correlaciones:
- En esta matriz las variables están representadas en las filas y en las columnas.
- Cada coeficiente expresa la correlación de una variable con otra. Por ejemplo, la correlación entre la variable de recompensa por esfuerzo y recompensa por inteligencia es 0.698.
- La información de cada coeficiente se repite sobre y bajo la diagonal, ya que es el mismo par de variables pero en el orden alterno.
- En la diagonal corresponde que todos los coeficientes sean 1, ya que la correlación de una variable consigo misma es perfectamente positiva. En esta tabla se omiten y aparece la diagonal vacía, ya que es información redundante. Por lo mismo, también se recomienda eliminar el triangulo superior de la tabla (redundante) de la siguiente manera:
| Recompensa: esfuerzo | Recompensa: talento | Estatus Social Subjetivo | Educación | Sexo | Edad | Meritocracia promedio | |
|---|---|---|---|---|---|---|---|
| Recompensa: esfuerzo | |||||||
| Recompensa: talento | 0.698*** | ||||||
| Estatus Social Subjetivo | -0.004 | 0.018 | |||||
| Educación | -0.122*** | -0.106*** | 0.290*** | ||||
| Sexo | -0.045* | -0.038* | -0.037* | -0.087*** | |||
| Edad | 0.096*** | 0.074*** | -0.066*** | -0.377*** | 0.061** | ||
| Meritocracia promedio | 0.920*** | 0.922*** | 0.008 | -0.123*** | -0.045* | 0.092*** | |
| Computed correlation used pearson-method with listwise-deletion. | |||||||
Una segunda forma de presentar matrices de correlaciones es de manera gráfica con la librería corrplot, cuya función corrplot.mixed corrplot::corrplot.mixedse aplica al objeto que generamos con la función cor (M):
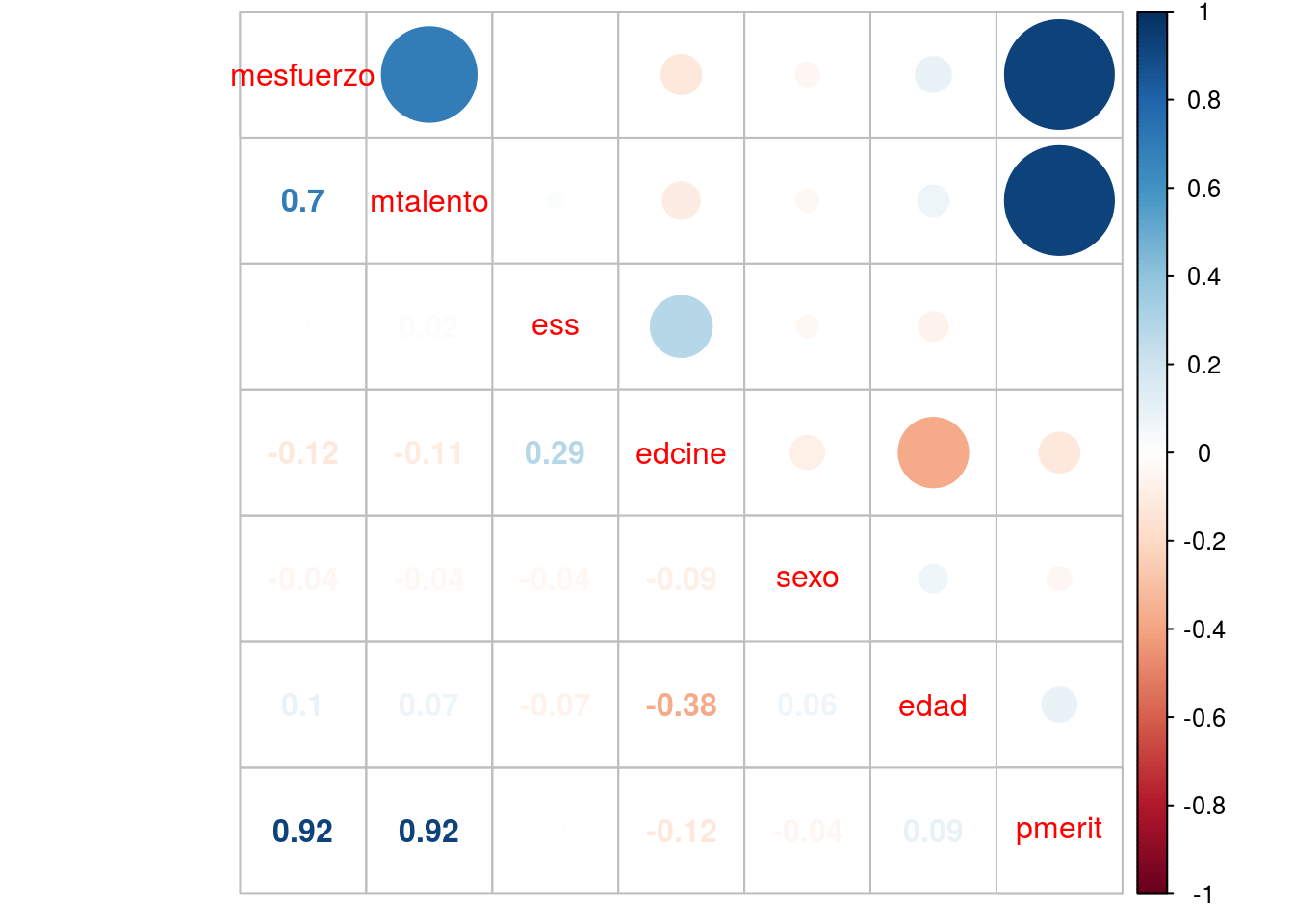
Este gráfico/matriz representa el grado de asociación entre variables mediante el tamaño de los círculos e intensidad de colores, y el signo de la asociación se representa con una gradiente de colores que va del azul (positivo) al rojo (negativo). Bajo la diagonal aparecen los indices de correlación entre pares de variables.
Finalmente, también se puede representar la correlación entre dos variables en un gráfico de nube de puntos o scatterplot:sjPlot::plot_scatter
## [1] "mesfuerzo" "mtalento" "ess" "edcine" "sexo" "edad"
## [7] "pmerit"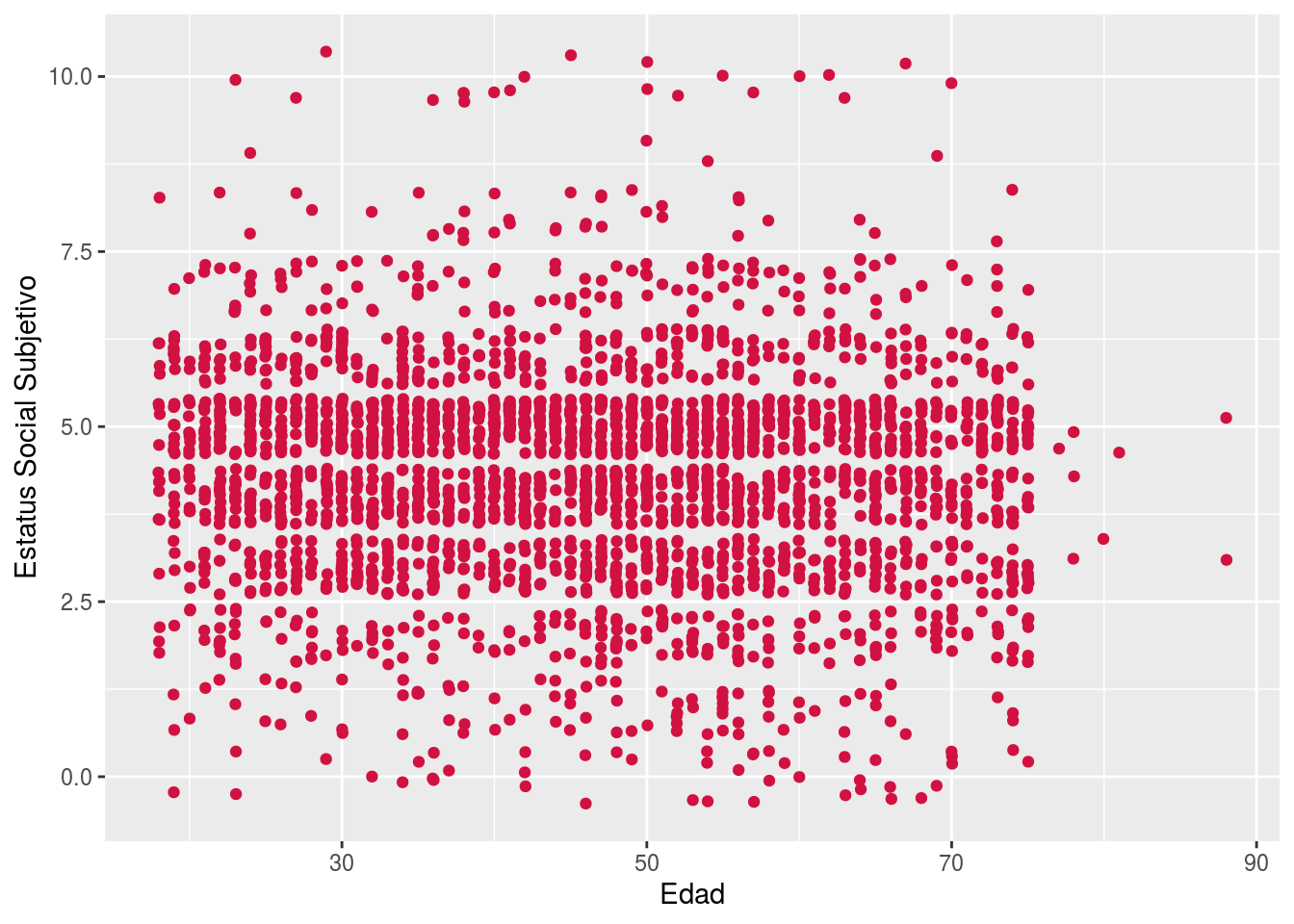
Donde:
- cada punto representa un caso
- la forma de la nube indica si la asociación es positiva, negativa o neutra:
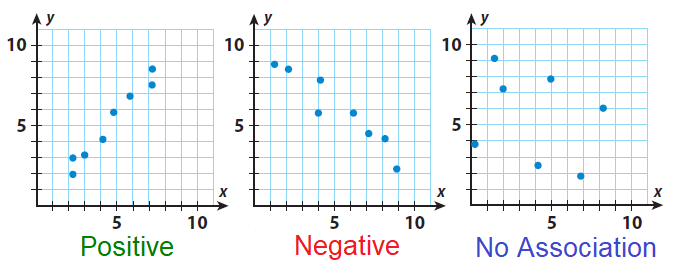
En el caso de nuestra nube de puntos entre edad y estatus social subjetivo, observamos que no hay asociación (lo que ya era indicado por su correlación de -0.07 observada en la matriz de correlaciones).
Nota final: Información de la sesión de R
R y sus librerías tienen distintas versiones. Esto puede representar algunos problemas de compatibilidad entre usuarios, por ejemplo, dos personas que trabajan en el mismo proyecto pero con distintas versiones (librerías y/o de R), pueden tener ocasionalmente complicaciones. Por eso, una buena práctica es registrar al final del código la información de la sesión. Y como siempre en R, varias maneras de hacer esto. Vamos con la más genérica que es muy simple: sessionInfo() sessionInfo()
## R version 4.0.0 (2020-04-24)
## Platform: x86_64-pc-linux-gnu (64-bit)
## Running under: Ubuntu 16.04.6 LTS
##
## Matrix products: default
## BLAS: /usr/lib/libblas/libblas.so.3.6.0
## LAPACK: /usr/lib/lapack/liblapack.so.3.6.0
##
## locale:
## [1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
## [3] LC_TIME=es_CL.UTF-8 LC_COLLATE=en_US.UTF-8
## [5] LC_MONETARY=es_CL.UTF-8 LC_MESSAGES=en_US.UTF-8
## [7] LC_PAPER=es_CL.UTF-8 LC_NAME=C
## [9] LC_ADDRESS=C LC_TELEPHONE=C
## [11] LC_MEASUREMENT=es_CL.UTF-8 LC_IDENTIFICATION=C
##
## attached base packages:
## [1] stats graphics grDevices utils datasets methods base
##
## other attached packages:
## [1] sessioninfo_1.1.1 corrplot_0.84 sjmisc_2.8.4 summarytools_0.9.6
## [5] sjstats_0.18.0 psych_1.9.12.31 Publish_2019.12.04 prodlim_2019.11.13
## [9] ggpubr_0.3.0 magrittr_1.5 car_3.0-7 carData_3.0-3
## [13] scales_1.1.1 gridExtra_2.3 ggplot2_3.3.0 stargazer_5.2.2
## [17] sjPlot_2.8.3 kableExtra_1.1.0 Rmisc_1.5 plyr_1.8.6
## [21] lattice_0.20-41 dplyr_0.8.5 knitr_1.28 pacman_0.5.1
##
## loaded via a namespace (and not attached):
## [1] TH.data_1.0-10 minqa_1.2.4 colorspace_1.4-1 pryr_0.1.4
## [5] ggsignif_0.6.0 ellipsis_0.3.0 rio_0.5.16 sjlabelled_1.1.4
## [9] estimability_1.3 parameters_0.6.1 base64enc_0.1-3 rstudioapi_0.11
## [13] fansi_0.4.1 mvtnorm_1.1-0 lubridate_1.7.8 xml2_1.3.2
## [17] codetools_0.2-16 splines_4.0.0 mnormt_1.5-7 nloptr_1.2.2.1
## [21] ggeffects_0.14.3 broom_0.5.6 effectsize_0.3.0 readr_1.3.1
## [25] compiler_4.0.0 httr_1.4.1 emmeans_1.4.6 backports_1.1.7
## [29] assertthat_0.2.1 Matrix_1.2-18 cli_2.0.2 htmltools_0.4.0
## [33] tools_4.0.0 coda_0.19-3 gtable_0.3.0 glue_1.4.1
## [37] Rcpp_1.0.4.6 cellranger_1.1.0 vctrs_0.3.0 nlme_3.1-147
## [41] blogdown_0.18 insight_0.8.4 xfun_0.13 stringr_1.4.0
## [45] openxlsx_4.1.5 lme4_1.1-23 rvest_0.3.5 lifecycle_0.2.0
## [49] statmod_1.4.34 rstatix_0.5.0 MASS_7.3-51.6 zoo_1.8-8
## [53] hms_0.5.3 parallel_4.0.0 sandwich_2.5-1 yaml_2.2.1
## [57] curl_4.3 pander_0.6.3 stringi_1.4.6 bayestestR_0.6.0
## [61] checkmate_2.0.0 boot_1.3-25 zip_2.0.4 lava_1.6.7
## [65] rlang_0.4.6 pkgconfig_2.0.3 matrixStats_0.56.0 evaluate_0.14
## [69] purrr_0.3.4 rapportools_1.0 tidyselect_1.1.0 bookdown_0.18
## [73] R6_2.4.1 magick_2.3 generics_0.0.2 multcomp_1.4-13
## [77] pillar_1.4.4 haven_2.2.0 foreign_0.8-79 withr_2.2.0
## [81] survival_3.1-12 abind_1.4-5 tibble_3.0.1 performance_0.4.6
## [85] modelr_0.1.7 crayon_1.3.4 rmarkdown_2.1 grid_4.0.0
## [89] readxl_1.3.1 data.table_1.12.8 forcats_0.5.0 digest_0.6.25
## [93] webshot_0.5.2 xtable_1.8-4 tidyr_1.0.3 munsell_0.5.0
## [97] viridisLite_0.3.0 tcltk_4.0.0Acá vemos un listado de información muy completo, desde versión de R, sistema operativo, opciones de idioma local (LOCALE), y muchas librerías. Si optamos por esta versión de la información de la sesión, lo importante es fijarse en (a) version de R, y (b) de las librerías cargadas al principio, que aquí aparecen bajo “other attached packages”.
La segunda opción permite obtener información más precisa, con sessioninfo sessioninfo()(la única diferencia con la anterior en el nombre es que info es con minúscula sessioninfo). Con un poco más de especificaciones de sintaxis se pueden obtener directamente los puntos (a) y (b) mencionados anteriormente:
## setting value
## version R version 4.0.0 (2020-04-24)
## os Ubuntu 16.04.6 LTS
## system x86_64, linux-gnu
## ui X11
## language en_US
## collate en_US.UTF-8
## ctype en_US.UTF-8
## tz America/Santiago
## date 2020-05-16## package * version date lib source
## car * 3.0-7 2020-03-11 [1] CRAN (R 4.0.0)
## carData * 3.0-3 2019-11-16 [1] CRAN (R 4.0.0)
## corrplot * 0.84 2017-10-16 [1] CRAN (R 4.0.0)
## dplyr * 0.8.5 2020-03-07 [1] CRAN (R 4.0.0)
## ggplot2 * 3.3.0 2020-03-05 [1] CRAN (R 4.0.0)
## ggpubr * 0.3.0 2020-05-04 [1] CRAN (R 4.0.0)
## gridExtra * 2.3 2017-09-09 [1] CRAN (R 4.0.0)
## kableExtra * 1.1.0 2019-03-16 [1] CRAN (R 4.0.0)
## knitr * 1.28 2020-02-06 [1] CRAN (R 4.0.0)
## lattice * 0.20-41 2020-04-02 [1] CRAN (R 4.0.0)
## magrittr * 1.5 2014-11-22 [1] CRAN (R 4.0.0)
## pacman * 0.5.1 2019-03-11 [1] CRAN (R 4.0.0)
## plyr * 1.8.6 2020-03-03 [1] CRAN (R 4.0.0)
## prodlim * 2019.11.13 2019-11-17 [1] CRAN (R 4.0.0)
## psych * 1.9.12.31 2020-01-08 [1] CRAN (R 4.0.0)
## Publish * 2019.12.04 2019-12-04 [1] CRAN (R 4.0.0)
## Rmisc * 1.5 2013-10-22 [1] CRAN (R 4.0.0)
## scales * 1.1.1 2020-05-11 [1] CRAN (R 4.0.0)
## sessioninfo * 1.1.1 2018-11-05 [1] CRAN (R 4.0.0)
## sjmisc * 2.8.4 2020-04-03 [1] CRAN (R 4.0.0)
## sjPlot * 2.8.3 2020-03-09 [1] CRAN (R 4.0.0)
## sjstats * 0.18.0 2020-05-06 [1] CRAN (R 4.0.0)
## stargazer * 5.2.2 2018-05-30 [1] CRAN (R 4.0.0)
## summarytools * 0.9.6 2020-03-02 [1] CRAN (R 4.0.0)
##
## [1] /home/juank/Dropbox/Rlibrary
## [2] /usr/local/lib/R/site-library
## [3] /usr/lib/R/site-library
## [4] /usr/lib/R/libraryResumen Práctica 2: Descripción de variables
En esta práctica revisamos los siguientes contenidos:
- tabla descriptiva general de variables
- tabla de asociación (o contingencia) entre dos variables categóricas
- tabla y gráfico de asociación entre variables categóricas y contínuas
- asociaciones entre pares de variables continuas mediante el índice de correlación.
Reporte de progreso
Completar el reporte de progreso correspondiente a esta práctica aquí
Archivo de código
El archivo de código R de esta práctica se puede descargar aquí