Práctica 11: Transformación de variables y supuestos de regresión
Índice
Objetivo
La siguiente práctica tiene el objetivo de introducir a los estudiantes en los supuestos y robustez del modelo de regresión. Por esta razón, volveremos a algunos de los contenidos previos relacionados con la estimación, análisis de residuos y ajuste. Para ello, utilizaremos la base de datos de la tercera ola del Estudio Longitudinal Social del Chile 2018 con el objetivo de analizar los determinantes de la Participación Ciudadana.
Datos
El Estudio Longitudinal Social del Chile (ENACOES 2014), único en Chile y América Latina, consiste en encuestar a casi 3.000 chilenos, anualmente, a lo largo de una década. ELSOC ha sido diseñado para evaluar la manera cómo piensan, sienten y se comportan los chilenos en torno a un conjunto de temas referidos al conflicto y la cohesión social en Chile. La población objetivo son hombres y mujeres entre 15 y 75 años de edad con un alcance nacional, donde se obtuvo una muestra final de 3748 casos en el año 2018.
#Cargamos la base de datos desde internet
load(url("https://multivariada.netlify.com/assignment/data/elsoc18p11.RData"))Explorar datos
A partir de la siguiente tabla se obtienen estadísticos descriptivos que luego serán relevantes para realizar las transformaciones y análisis posteriores.
| No | Variable | Label | Stats / Values | Freqs (% of Valid) | Graph | Valid | Missing | ||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | sexo [numeric] | Sexo entrevistado | Min : 0 Mean : 0.6 Max : 1 |
|
 |
3748 (100%) | 0 (0%) | ||||||||||||||||||||||||||||||
| 2 | edad [numeric] | Edad entrevistado | Mean (sd) : 47.1 (15.5) min < med < max: 18 < 47 < 90 IQR (CV) : 25 (0.3) | 70 distinct values |  |
3748 (100%) | 0 (0%) | ||||||||||||||||||||||||||||||
| 3 | educ [factor] | Nivel educacional | 1. 1 2. 2 3. 3 4. 4 5. 5 |
|
 |
3743 (99.87%) | 5 (0.13%) | ||||||||||||||||||||||||||||||
| 4 | pospol [factor] | Autoubicacion escala izquierda-derecha | 1. 1 2. 2 3. 3 4. 4 |
|
 |
3664 (97.76%) | 84 (2.24%) | ||||||||||||||||||||||||||||||
| 5 | part01 [numeric] | Frecuencia: Firma carta o peticion apoyando causa | Mean (sd) : 1.5 (0.9) min < med < max: 1 < 1 < 5 IQR (CV) : 1 (0.6) |
|
 |
3742 (99.84%) | 6 (0.16%) | ||||||||||||||||||||||||||||||
| 6 | part02 [numeric] | Frecuencia: Asiste a marcha o manifestacion pacifica | Mean (sd) : 1.2 (0.6) min < med < max: 1 < 1 < 5 IQR (CV) : 0 (0.5) |
|
 |
3745 (99.92%) | 3 (0.08%) | ||||||||||||||||||||||||||||||
| 7 | part03 [numeric] | Frecuencia: Participa en huelga | Mean (sd) : 1.2 (0.5) min < med < max: 1 < 1 < 5 IQR (CV) : 0 (0.5) |
|
 |
3745 (99.92%) | 3 (0.08%) | ||||||||||||||||||||||||||||||
| 8 | part04 [numeric] | Frecuencia: Usa redes sociales para opinar en temas publicos | Mean (sd) : 1.6 (1.1) min < med < max: 1 < 1 < 5 IQR (CV) : 1 (0.7) |
|
 |
3743 (99.87%) | 5 (0.13%) | ||||||||||||||||||||||||||||||
| 9 | inghogar [numeric] | Ingreso total del hogar | Mean (sd) : 678842.5 (781003.9) min < med < max: 30000 < 5e+05 < 1.7e+07 IQR (CV) : 5e+05 (1.2) | 227 distinct values |  |
3080 (82.18%) | 668 (17.82%) | ||||||||||||||||||||||||||||||
| 10 | inghogar_t [numeric] | Ingreso total del hogar (en tramos) | Mean (sd) : 7 (5.4) min < med < max: 1 < 5 < 20 IQR (CV) : 7 (0.8) | 20 distinct values |  |
477 (12.73%) | 3271 (87.27%) | ||||||||||||||||||||||||||||||
| 11 | tamhogar [numeric] | Habitantes del hogar | Mean (sd) : 3.2 (1.6) min < med < max: 1 < 3 < 14 IQR (CV) : 2 (0.5) | 13 distinct values |  |
3741 (99.81%) | 7 (0.19%) |
Generated by summarytools 0.9.6 (R version 4.0.0)
2020-08-17
| ID | Name | Label | Values | Value Labels |
|---|---|---|---|---|
| 1 | sexo | Sexo entrevistado |
0 1 |
Hombre Mujer |
| 2 | edad | Edad entrevistado | range: 18-90 | |
| 3 | educ | Nivel educacional |
1 2 3 4 5 |
Primaria incompleta menos Primaria y secundaria baja Secundaria alta Terciaria ciclo corto Terciaria y Postgrado |
| 4 | pospol | Autoubicacion escala izquierda-derecha |
1 2 3 4 |
Derecha Centro Izquierda Indep./Ninguno |
| 5 | part01 | Frecuencia: Firma carta o peticion apoyando causa |
1 2 3 4 5 |
Nunca Casi nunca A veces Frecuentemente Muy frecuentemente |
| 6 | part02 |
Frecuencia: Asiste a mbackground-color:#eeeeeeha o manifestacion pacifica |
1 2 3 4 5 |
Nunca Casi nunca A veces Frecuentemente Muy frecuentemente |
| 7 | part03 | Frecuencia: Participa en huelga |
1 2 3 4 5 |
Nunca Casi nunca A veces Frecuentemente Muy frecuentemente |
| 8 | part04 |
Frecuencia: Usa redes sociales para opinar en temas publicos |
1 2 3 4 5 |
Nunca Casi nunca A veces Frecuentemente Muy frecuentemente |
| 9 | inghogar | Ingreso total del hogar | range: 30000-17000000 | |
| 10 | inghogar_t | Ingreso total del hogar (en tramos) |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
Menos de $220.000 mensuales liquidos De $220.001 a $280.000 mensuales liquidos De $280.001 a $330.000 mensuales liquidos De $330.001 a $380.000 mensuales liquidos De $380.001 a $420.000 mensuales liquidos De $420.001 a $470.000 mensuales liquidos De $470.001 a $510.000 mensuales liquidos De $510.001 a $560.000 mensuales liquidos De $560.001 a $610.000 mensuales liquidos De $610.001 a $670.000 mensuales liquidos De $670.001 a $730.000 mensuales liquidos De $730.001 a $800.000 mensuales liquidos De $800.001 a $890.000 mensuales liquidos De $890.001 a $980.000 mensuales liquidos De $980.001 a $1.100.000 mensuales liquidos De $1.100.001 a $1.260.000 mensuales liquidos De $1.260.001 a $1.490.000 mensuales liquidos De $1.490.001 a $1.850.000 mensuales liquidos De $1.850.001 a $2.700.000 mensuales liquidos Mas de $2.700.000 a mensuales liquidos |
| 11 | tamhogar | Habitantes del hogar | range: 1-14 | |
Medición y transformación de variables
Creación de índice
En ELSOC existen cuatro preguntas referentes a la participación política o ciudadana, donde se le pregunta a las personas por la frecuencia en que han participado de determinados eventos vinculados a su rol como ciudadanos. Para esto, se emplearon escalas likert de 5 categorías para medir dicha participación.
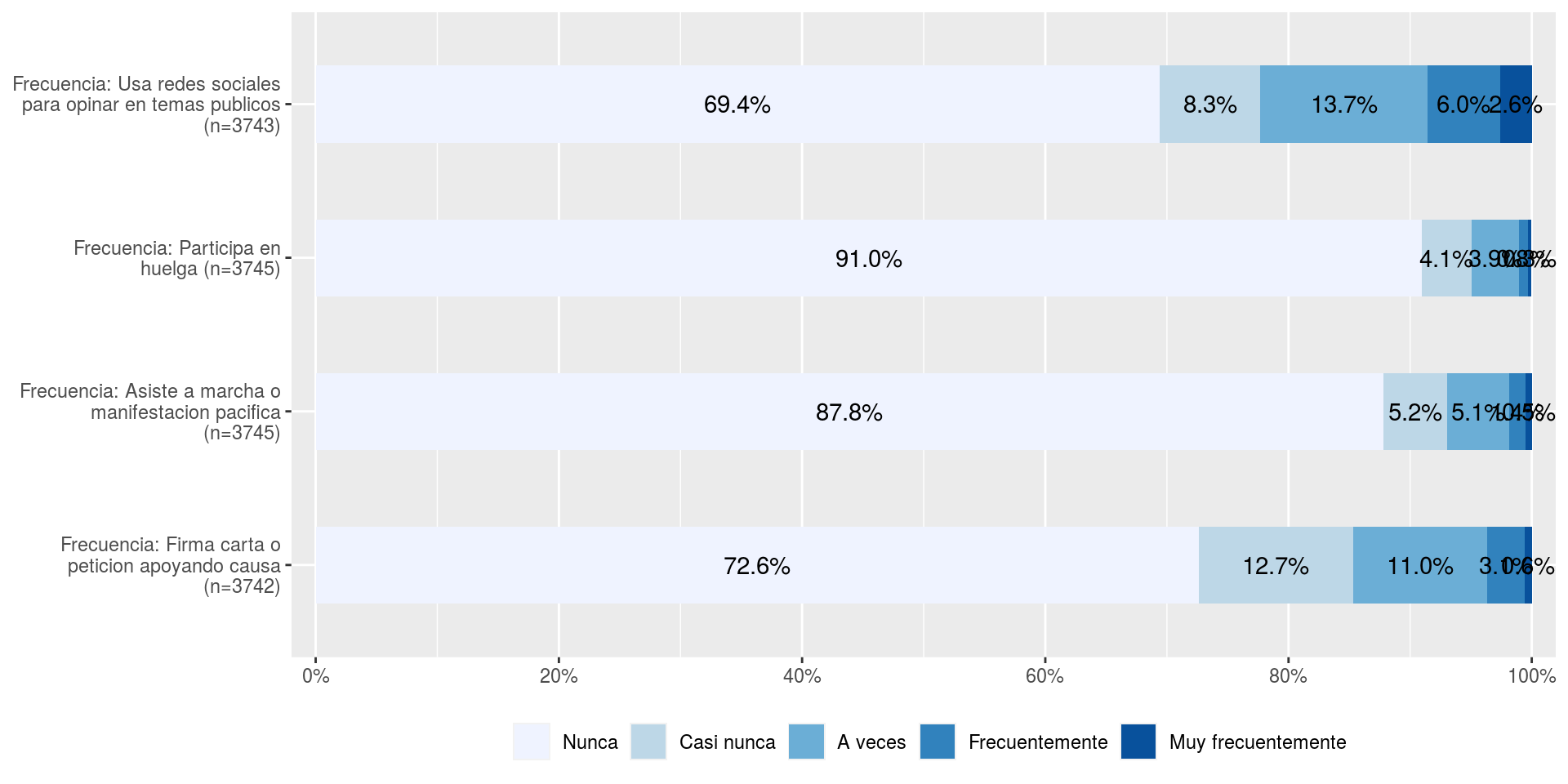
En la figura anterior, podemos ver que existe un alto porcentaje de personas que declaran no haber participado nunca en alguna de estas expresiones de la participación ciudadana. En este sentido, para la creación de un índice o medida agrupada, nos interesa saber si existe algún grado de relación entre nuestros indicadores. Para esto, lo que tradicionalmente se realiza es realizar un análisis de correlación entre los indicadores.

La matriz de correlación nos indica que existen correlaciones moderadas entre los indicadores, donde 0.25 es la más baja y 0.44 la más alta. Es muy importante realizar este paso, debido a que si nuestros indicadores no correlacionan en absoluto, es posible que estemos frente a un atributo distinto. Por lo tanto, sería poco adecuado realizar la construcción de un índice que busque representar un fenómeno o constructo “común” a través de indicadores que no poseen ningún grado de correlación. En nuestro caso, hemos decidido elaborar un índice sumatorio a través de la suma de las respuestas de cada individuo. Para ello emplearemos las funciones mutate (para crear una nueva variable) y rowSums() (para sumar los indicadores) de la librería dplyr.
| Mean | Std.Dev | Min | Median | Max | N.Valid | Pct.Valid | |
|---|---|---|---|---|---|---|---|
| partpol | 5.47 | 2.30 | 4.00 | 4.00 | 20.00 | 3740.00 | 99.79 |
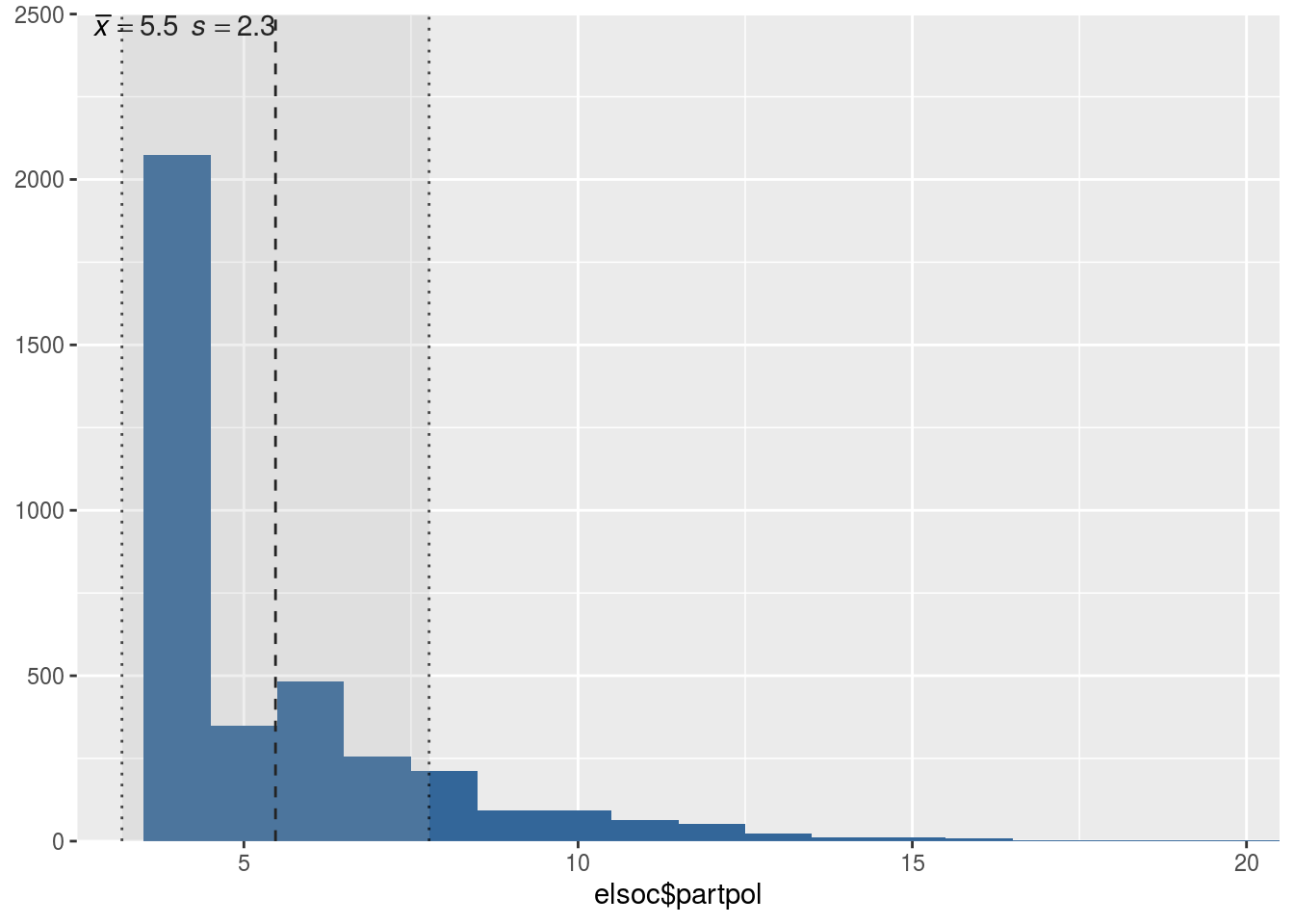
Vemos que el índice sumatorio posee valores que van desde 4 hasta 20, con una media de 5,47 y una mediana de 4. Además, vemos algo que ya se había identificado en el gráfico descriptivo de cada indicador por separado, el hecho que existe una proporción importante de personas que respondieron “nunca” en los cuatro indicadores, los cuales son representados por una alta frecuencia de 4 en el histograma. Con esto hemos creado nuestro índice sumatorio de Participación Política.
Recuperar casos perdidos
Es común que en las encuestas sociales cierta variables posean una alta proporción de datos perdidos. Un ejemplo común es en el reporte de los ingresos de los hogares o individuos. Esto generalmente puede generarse por características de la persona (p.ej. desempleado, estudiante) o por deseabilidad social (personas de altos ingresos desisten de reportar). En el caso de ELSOC, existen dos estrategias para solicitar que las personas reporten sus ingresos. La primera consiste en preguntar directamente por el monto en pesos chilenos de los ingresos totales del hogar. Alternativamente, si la persona no reporta los ingresos, se le presenta la posibilidad de ubicar los ingresos del hogar en tramos (Por ejemplo “De $560.001 a $610.000 mensuales liquidos”). De esta manera, si existen datos perdidos en la primera, se emplea la segunda pregunta para tener un nivel aproximado del ingreso del hogar.
| Mean | Std.Dev | Min | Median | Max | N.Valid | Pct.Valid | |
|---|---|---|---|---|---|---|---|
| inghogar | 678842.52 | 781003.92 | 30000.00 | 5e+05 | 1.7e+07 | 3080.00 | 82.18 |
|
Si observamos la tabla de descriptivos para la variable ingreso del hogar (inghogar), tenemos un porcentaje 17,82% de datos perdidos. Por esta razón, emplearemos los datos disponibles en inghogar_t para recuperar información en los ingresos del hogar.
La estrategia posee los siguientes pasos:
- Calcular la media del tramo reportado.
- En el caso de que la persona no haya reportado el monto de los ingresos del hogar, remplazamos este valor perdido por el valor de la media del tramo, en el caso de estar disponible.
- Comparamos la variable original con la nueva variable que posee información recuperada.
Paso 1: Calcular la media por cada tramo
elsoc$inghogar_t[elsoc$inghogar_t==1] <-( 220000 ) # [1] "Menos de $220.000 mensuales liquidos"
elsoc$inghogar_t[elsoc$inghogar_t==2] <-(220001 +280000 )/2 # [2] "De $220.001 a $280.000 mensuales liquidos"
elsoc$inghogar_t[elsoc$inghogar_t==3] <-(280001 +330000 )/2 # [3] "De $280.001 a $330.000 mensuales liquidos"
elsoc$inghogar_t[elsoc$inghogar_t==4] <-(330001 +380000 )/2 # [4] "De $330.001 a $380.000 mensuales liquidos"
elsoc$inghogar_t[elsoc$inghogar_t==5] <-(380001 +420000 )/2 # [5] "De $380.001 a $420.000 mensuales liquidos"
elsoc$inghogar_t[elsoc$inghogar_t==6] <-(420001 +470000 )/2 # [6] "De $420.001 a $470.000 mensuales liquidos"
elsoc$inghogar_t[elsoc$inghogar_t==7] <-(470001 +510000 )/2 # [7] "De $470.001 a $510.000 mensuales liquidos"
elsoc$inghogar_t[elsoc$inghogar_t==8] <-(510001 +560000 )/2 # [8] "De $510.001 a $560.000 mensuales liquidos"
elsoc$inghogar_t[elsoc$inghogar_t==9] <-(560001 +610000 )/2 # [9] "De $560.001 a $610.000 mensuales liquidos"
elsoc$inghogar_t[elsoc$inghogar_t==10]<-(610001 +670000 )/2 # [10] "De $610.001 a $670.000 mensuales liquidos"
elsoc$inghogar_t[elsoc$inghogar_t==11]<-(670001 +730000 )/2 # [11] "De $670.001 a $730.000 mensuales liquidos"
elsoc$inghogar_t[elsoc$inghogar_t==12]<-(730001 +800000 )/2 # [12] "De $730.001 a $800.000 mensuales liquidos"
elsoc$inghogar_t[elsoc$inghogar_t==13]<-(800001 +890000 )/2 # [13] "De $800.001 a $890.000 mensuales liquidos"
elsoc$inghogar_t[elsoc$inghogar_t==14]<-(890001 +980000 )/2 # [14] "De $890.001 a $980.000 mensuales liquidos"
elsoc$inghogar_t[elsoc$inghogar_t==15]<-(980001 +1100000)/2 # [15] "De $980.001 a $1.100.000 mensuales liquidos"
elsoc$inghogar_t[elsoc$inghogar_t==16]<-(1100001+1260000)/2 # [16] "De $1.100.001 a $1.260.000 mensuales liquidos"
elsoc$inghogar_t[elsoc$inghogar_t==17]<-(1260001+1490000)/2 # [17] "De $1.260.001 a $1.490.000 mensuales liquidos"
elsoc$inghogar_t[elsoc$inghogar_t==18]<-(1490001+1850000)/2 # [18] "De $1.490.001 a $1.850.000 mensuales liquidos"
elsoc$inghogar_t[elsoc$inghogar_t==19]<-(1850001+2700000)/2 # [19] "De $1.850.001 a $2.700.000 mensuales liquidos"
elsoc$inghogar_t[elsoc$inghogar_t==20]<-(2700000) # [20] "Mas de $2.700.000 a mensuales liquidos"Paso 2: En el caso de no tener información, remplazar por la media del tramo
elsoc$inghogar_i <- ifelse(test = (is.na(elsoc$inghogar)), #¿existen NA en ingresos?
yes = elsoc$inghogar_t, #VERDADERO, remplazar con la media del tramo
no = elsoc$inghogar) #FALSE, mantener la variable original.
elsoc$inghogar_i <- set_label(elsoc$inghogar_i,"Ingreso total del hogar (imputada)")Paso 3: Comparamos la variable original con la nueva
sjmisc::descr(elsoc[,c("inghogar","inghogar_i")],
show =c("label", "n", "NA.prc", "mean", "md","sd")) %>% knitr::kable(digits = 2)| var | label | n | NA.prc | mean | sd | md |
|---|---|---|---|---|---|---|
| inghogar | Ingreso total del hogar | 3080 | 17.82 | 678842.5 | 781003.9 | 500000 |
| inghogar_i | Ingreso total del hogar (imputada) | 3557 | 5.10 | 668539.5 | 752608.2 | 480000 |
Vemos que pasamos de tener 17,82% de datos perdidos a un 5,1%, es decir recuperamos un 12,72% de los casos que antes tenían datos perdidos en la variable ingreso. Con estos datos podemos calcular el ingreso per capita del hogar, empleando la variable habitantes del hogar (tamhogar).
elsoc$ing_pcap <- elsoc$inghogar_i/elsoc$tamhogar
elsoc$ing_pcap <- set_label(elsoc$ing_pcap,"Ingreso per cápita del hogar")sjmisc::descr(elsoc[,c("inghogar","inghogar_i","tamhogar","ing_pcap")],
show =c("label", "n", "NA.prc", "mean", "md","sd")) %>% knitr::kable(digits = 2)| var | lab | el | n NA | .prc | mean | sd | md |
|---|---|---|---|---|---|---|---|
| 1 | inghogar | Ingreso total del hogar | 3080 | 17.82 | 678842.52 | 781003.92 | 500000.0 |
| 2 | inghogar_i | Ingreso total del hogar (imputada) | 3557 | 5.10 | 668539.54 | 752608.16 | 480000.0 |
| 4 | tamhogar | Habitantes del hogar | 3741 | 0.19 | 3.16 | 1.57 | 3.0 |
| 3 | ing_pcap | Ingreso per cápita del hogar | 3552 | 5.23 | 263057.71 | 350338.36 | 166666.7 |
Vemos que la variable tamhogar posee un 0,19% de datos perdidos, por lo cual, al calcular el ingreso per cápita, vemos que el porcentaje de casos sin información en la nueva variable aumenta levemente a un 5,23%.
Ingresos como variable categórica
Teniendo el ingreso per cápita del hogar, podemos calcular categorías de ingresos tales como los quintiles (o deciles). Por lo tanto, podemos clasificar a los individuos según sus ingresos en una variable categórica.
El procedimiento es el siguiente:
elsoc$quintile<- dplyr::ntile(x = elsoc$ing_pcap,
n = 5) # n de categorias, para quintiles usamos 5
elsoc$quintile <- factor(elsoc$quintile,c(1,2,3,4,5), c("Quintil 1","Quintil 2","Quintil 3","Quintil 4","Quintil 5"))
elsoc %>%
group_by(quintile) %>%
summarise(n=n(),
Media=mean(ing_pcap,na.rm = T),
Mediana=median(ing_pcap,na.rm = T)) %>%
knitr::kable()| quintile | n | Media | Mediana |
|---|---|---|---|
| Quintil 1 | 711 | 62859.09 | 66666.67 |
| Quintil 2 | 711 | 112218.97 | 111250.12 |
| Quintil 3 | 710 | 167748.23 | 166666.67 |
| Quintil 4 | 710 | 262710.27 | 250000.50 |
| Quintil 5 | 710 | 710246.41 | 500000.00 |
| 196 |
En la tabla podemos observar que la variable quintile posee 5 grupos de tamaño equivalente. Además, agregamos la media y la mediana de los ingresos para cada categoría para ilustrar que podemos tratar esta variable como categórica y ordinal.
Existe una última estrategia que podemos utilizar para recuperar ese 5,23% (n=196) de casos perdidos. Para esto, generamos una categoría adicional para los datos perdidos, es decir, recodificamos los NA para que se incluyan como una nueva categoría.
El procedimiento es el siguiente:
elsoc$quintilemiss <- factor(elsoc$quintile,ordered = T)
elsoc$quintilemiss <- ifelse(is.na(elsoc$quintilemiss),yes = 6,no = elsoc$quintilemiss)
elsoc$quintilemiss <- factor(elsoc$quintilemiss ,levels = c(1,2,3,4,5,6),labels = c("Quintil 1","Quintil 2","Quintil 3","Quintil 4","Quintil 5","Missing"))
elsoc %>% group_by(quintilemiss) %>% summarise(n=n())A tibble: 6 x 2
quintilemiss n
Teniendo una nueva categoría de ingresos, podemos recuperar estos casos para los posteriores análisis. A continuación, se llevaran a cabo una serie de análisis que nos permitirán comprar los resultados según distintas especificaciones y empleando distintas maneras de operacionalizar la variable ingresos.
Estimación
fit01<- lm(partpol~sexo+edad+ing_pcap+pospol,data=elsoc)
fit02<- lm(partpol~sexo+edad+quintile+pospol,data=elsoc)
fit03<- lm(partpol~sexo+edad+quintilemiss+pospol,data=elsoc)labs01 <- c("Intercepto","Sexo (mujer=1)","Edad","Ingreso per/cap","Centro (ref. derecha)","Izquierda","Idep./Ninguno",
"Quintil 2","Quintil 3","Quintil 4","Quintil 5",
"Quintil 2","Quintil 3","Quintil 4","Quintil 5","Quintil perdido")
htmlreg(list(fit01,fit02,fit03),doctype = FALSE,
custom.model.names = c("Modelo 1","Modelo 2","Modelo 3"),
custom.coef.names = labs01)| Modelo 1 | Modelo 2 | Modelo 3 | ||
|---|---|---|---|---|
| Intercepto | 8.27*** | 7.94*** | 7.97*** | |
| (0.14) | (0.16) | (0.16) | ||
| Sexo (mujer=1) | 0.05 | 0.13 | 0.12 | |
| (0.07) | (0.08) | (0.07) | ||
| Edad | -0.04*** | -0.04*** | -0.04*** | |
| (0.00) | (0.00) | (0.00) | ||
| Ingreso per/cap | 0.00*** | |||
| (0.00) | ||||
| Centro (ref. derecha) | -1.02*** | -1.04*** | -1.04*** | |
| (0.10) | (0.10) | (0.10) | ||
| Izquierda | -1.10*** | -1.12*** | -1.13*** | |
| (0.11) | (0.11) | (0.11) | ||
| Idep./Ninguno | -1.59*** | -1.58*** | -1.60*** | |
| (0.10) | (0.10) | (0.10) | ||
| Quintil 2 | 0.22 | 0.21 | ||
| (0.11) | (0.11) | |||
| Quintil 3 | 0.51*** | 0.51*** | ||
| (0.11) | (0.11) | |||
| Quintil 4 | 0.51*** | 0.50*** | ||
| (0.11) | (0.11) | |||
| Quintil 5 | 0.89*** | 0.88*** | ||
| (0.12) | (0.12) | |||
| Quintil perdido | 0.59*** | |||
| (0.18) | ||||
| R2 | 0.17 | 0.17 | 0.17 | |
| Adj. R2 | 0.16 | 0.17 | 0.17 | |
| Num. obs. | 3475 | 3475 | 3656 | |
| RMSE | 2.10 | 2.09 | 2.10 | |
| p < 0.001, p < 0.01, p < 0.05 | ||||
Diágnosticos
Casos influyentes
Para determinar si un outlier es un caso influyente, es decir que su presencia/ausencia genera un cambio importante en la estimación de los coeficientes de regresión, calculamos la Distancia de Cook..
Posteriormente, se establece un punto de corte de \(4/(n-k-1)\):
n<- nobs(fit03) #n de observaciones
k<- length(coef(fit03)) # n de parametros
dcook<- 4/(n-k-1) #punt de corteSi lo graficamos se ve de la siguiente manera:
final <- broom::augment_columns(fit03,data = elsoc)
final$id <- as.numeric(row.names(final))
# identify obs with Cook's D above cutoff
ggplot(final, aes(id, .cooksd))+
geom_bar(stat="identity", position="identity")+
xlab("Obs. Number")+ylab("Cook's distance")+
geom_hline(yintercept=dcook)+
geom_text(aes(label=ifelse((.cooksd>dcook),id,"")),
vjust=-0.2, hjust=0.5)
Identificamos los casos influyentes y filtramos la base de datos:
Estimación sin casos influyentes:
labs02 <- c("Intercepto","Sexo (mujer=1)","Edad",
"Quintil 2","Quintil 3","Quintil 4","Quintil 5","Quintil perdido",
"Izquierda (ref. derecha)","Centro","Idep./Ninguno")
htmlreg(list(fit03,fit04),
doctype = FALSE,
custom.model.names = c("Modelo 3", "Modelo 4"),
custom.coef.names = labs02)| Modelo 3 | Modelo 4 | ||
|---|---|---|---|
| Intercepto | 7.97*** | 7.05*** | |
| (0.16) | (0.11) | ||
| Sexo (mujer=1) | 0.12 | 0.07 | |
| (0.07) | (0.05) | ||
| Edad | -0.04*** | -0.03*** | |
| (0.00) | (0.00) | ||
| Quintil 2 | 0.21 | 0.11 | |
| (0.11) | (0.08) | ||
| Quintil 3 | 0.51*** | 0.34*** | |
| (0.11) | (0.08) | ||
| Quintil 4 | 0.50*** | 0.32*** | |
| (0.11) | (0.08) | ||
| Quintil 5 | 0.88*** | 0.57*** | |
| (0.12) | (0.08) | ||
| Quintil perdido | 0.59*** | 0.31* | |
| (0.18) | (0.13) | ||
| Izquierda (ref. derecha) | -1.04*** | -0.65*** | |
| (0.10) | (0.07) | ||
| Centro | -1.13*** | -0.71*** | |
| (0.11) | (0.08) | ||
| Idep./Ninguno | -1.60*** | -1.14*** | |
| (0.10) | (0.07) | ||
| R2 | 0.17 | 0.18 | |
| Adj. R2 | 0.17 | 0.18 | |
| Num. obs. | 3656 | 3460 | |
| RMSE | 2.10 | 1.48 | |
| p < 0.001, p < 0.01, p < 0.05 | |||
En términos generales, el sentido y significación estadística de los coeficientes del Modelo 4 se mantiene respecto al Modelo 3. Adicionalmente, si observamos que el modelo sin casos influyentes presenta una mejora en ajuste. Por lo tanto, los análisis posteriores se realizaran en base a este modelo.
Linealidad
Para analizar la linealidad respecto de un modelo de regresión, debemos analizar la distribución de los residuos con respecto a la recta de regresión.
- Los residuos deben ser independientes de los valores predichos (fitted values).
- Cualquier correlación entre residuo y valores predichos violarían este supuesto.
- La presencia de un patrón no lineal, es señal de que el modelo está especificado incorrectamente.
ggplot(fit04, aes(.fitted, .resid)) +
geom_point() +
geom_hline(yintercept = 0) +
geom_smooth(se = TRUE)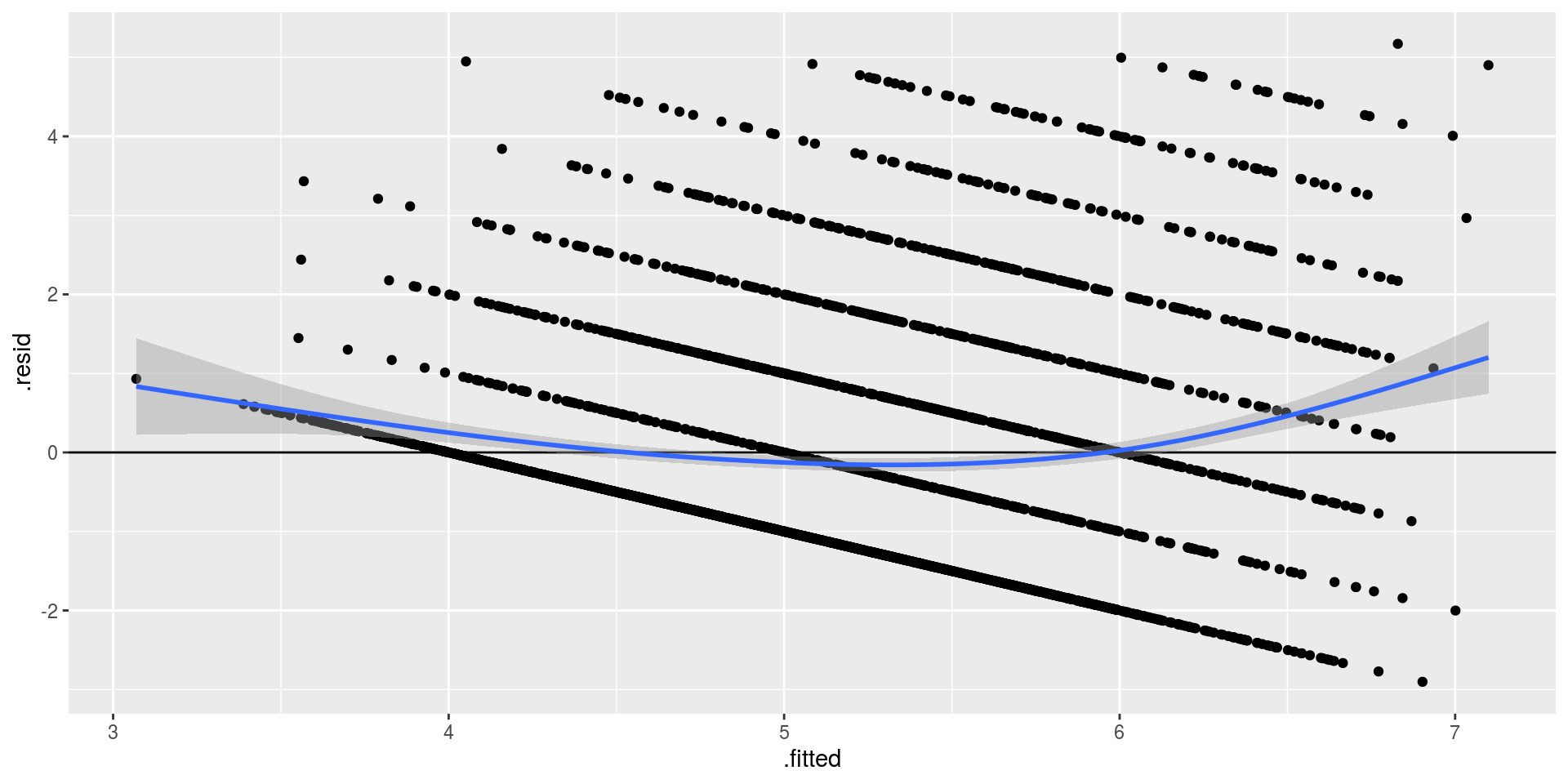
Figure 1: Relación entre residuos y valores predichos
El gráfico nos indica que existe un patrón en la distribución de los residuos. Para intentar mejorar la estimación podemos realizar una transformación de variables. A continuación presentaremos un ejemplo para la Edad y para los Ingresos.
- Polinomio: \(\text{Edad}^2\)
elsoc02$edad2 <- elsoc02$edad^2
fit05<- lm(partpol~sexo+edad+edad2+quintilemiss+pospol,data=elsoc02)edad<- fit05$model$edad
fit<- fit05$fitted.values
data01 <- as.data.frame(cbind(edad,fit))
ggplot(data01, aes(x = edad, y = fit)) +
theme_bw() +
geom_point()+
geom_smooth()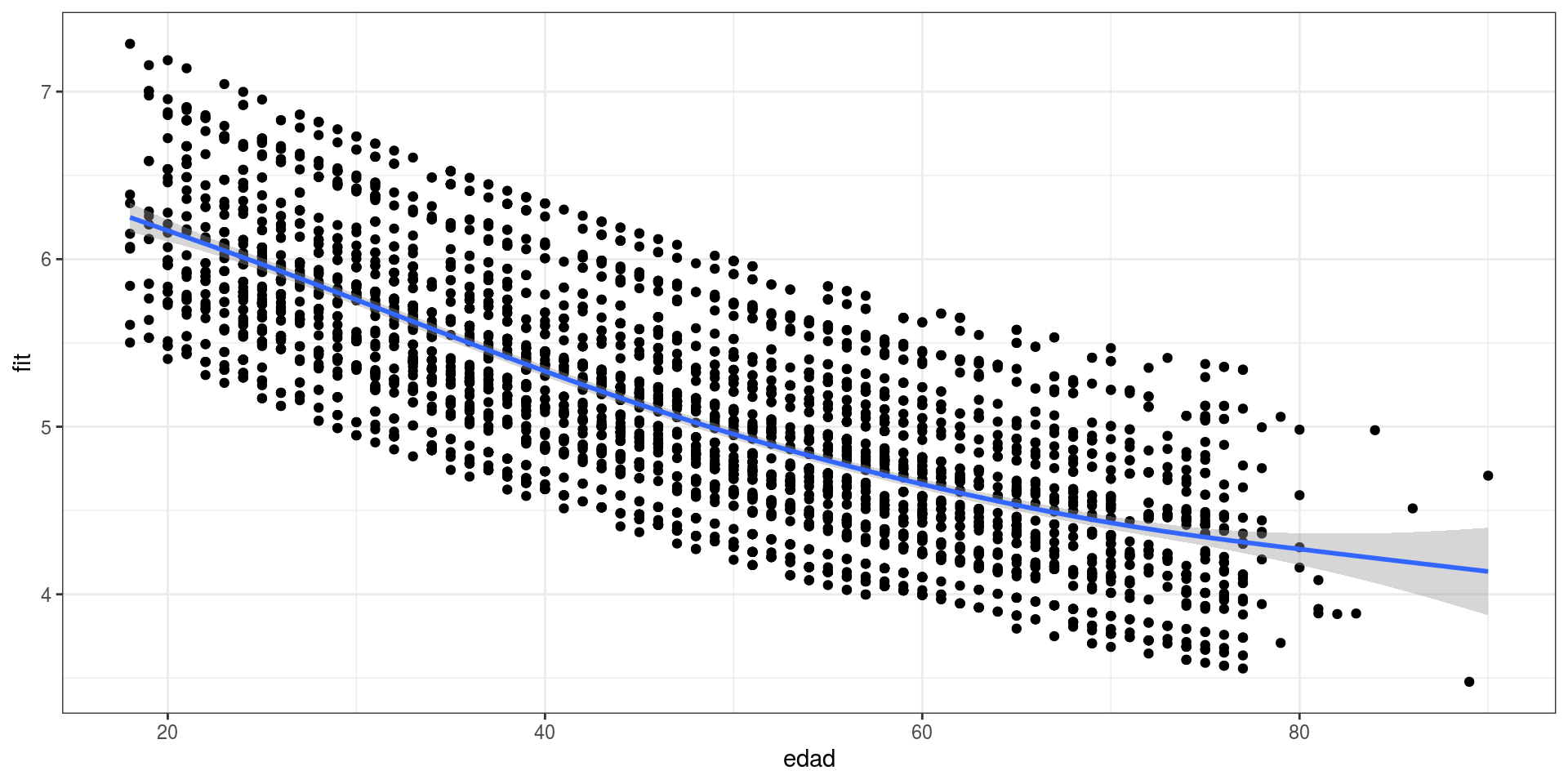
Figure 2: Efecto cuadrático de la edad (Modelo 5)
- Logaritmo: \(\log(\text{ingreso})\)
elsoc02$lningreso <- log(elsoc02$ing_pcap)
elsoc02$lningreso <- set_label(elsoc02$lningreso,"log(ingreso per cap)")
fit06 <- lm(partpol~sexo+edad+edad2+lningreso+pospol,data=elsoc02)plot_frq(elsoc02$ing_pcap,type = "hist",normal.curve = T, show.mean = T)
plot_frq(elsoc02$lningreso,type = "hist", normal.curve = T,show.mean = T)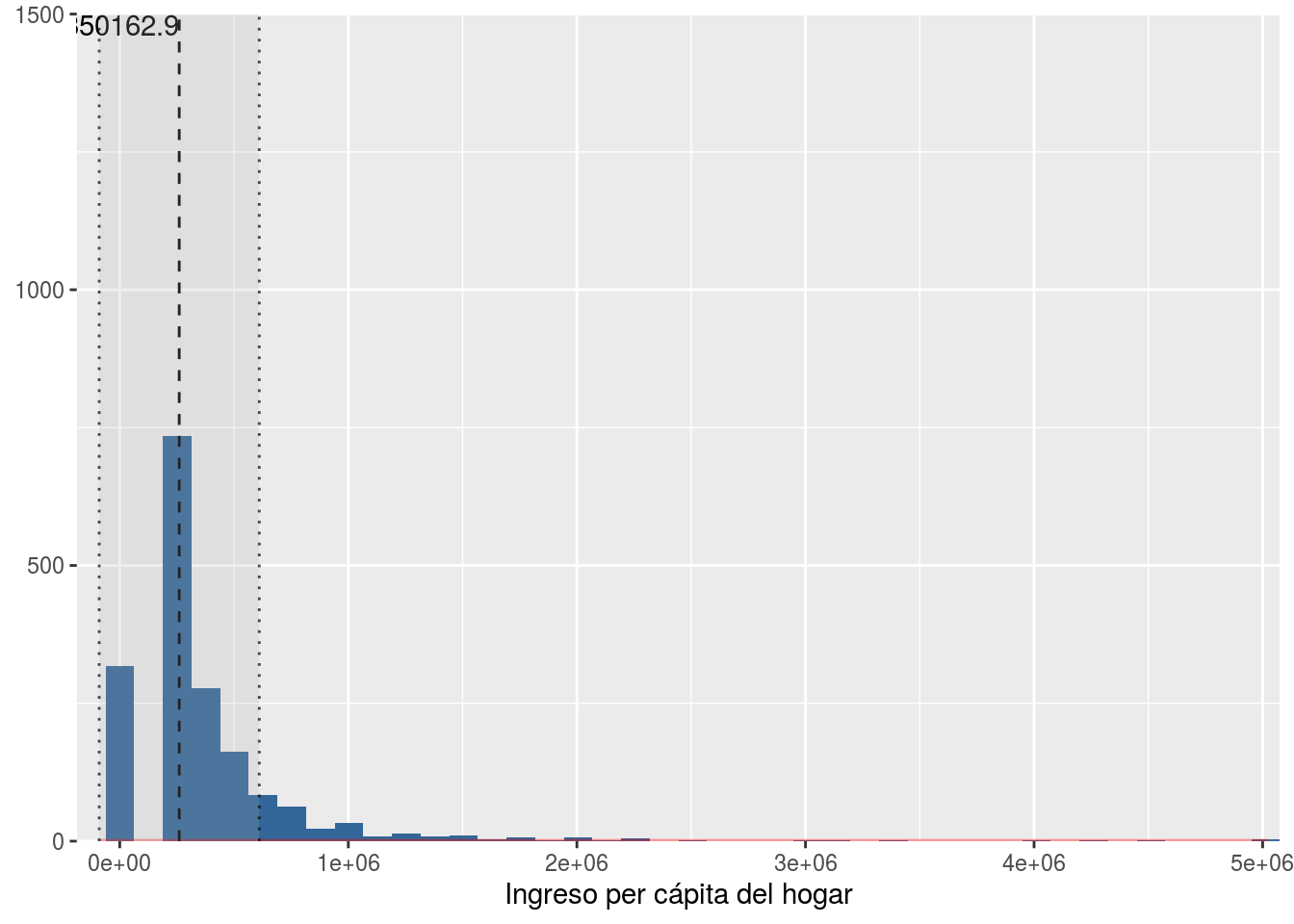

labs03 <- c("Intercepto","Sexo (mujer=1)","Edad",
"Quintil 2","Quintil 3","Quintil 4","Quintil 5","Quintil perdido",
"Izquierda (ref. derecha)","Centro","Idep./Ninguno", "Edad²","Ingreso per cap (log)")
htmlreg(list(fit04, fit05, fit06), doctype = FALSE,
custom.model.names = c("Modelo 4", "Modelo 5", "Modelo 6"),
custom.coef.names = labs03)| Modelo 4 | Modelo 5 | Modelo 6 | ||
|---|---|---|---|---|
| Intercepto | 7.05*** | 7.62*** | 4.98*** | |
| (0.11) | (0.24) | (0.46) | ||
| Sexo (mujer=1) | 0.07 | 0.08 | 0.09 | |
| (0.05) | (0.05) | (0.05) | ||
| Edad | -0.03*** | -0.06*** | -0.06*** | |
| (0.00) | (0.01) | (0.01) | ||
| Quintil 2 | 0.11 | 0.11 | ||
| (0.08) | (0.08) | |||
| Quintil 3 | 0.34*** | 0.34*** | ||
| (0.08) | (0.08) | |||
| Quintil 4 | 0.32*** | 0.32*** | ||
| (0.08) | (0.08) | |||
| Quintil 5 | 0.57*** | 0.57*** | ||
| (0.08) | (0.08) | |||
| Quintil perdido | 0.31* | 0.31* | ||
| (0.13) | (0.13) | |||
| Izquierda (ref. derecha) | -0.65*** | -0.65*** | -0.63*** | |
| (0.07) | (0.07) | (0.08) | ||
| Centro | -0.71*** | -0.70*** | -0.70*** | |
| (0.08) | (0.08) | (0.08) | ||
| Idep./Ninguno | -1.14*** | -1.13*** | -1.12*** | |
| (0.07) | (0.07) | (0.07) | ||
| Edad² | 0.00** | 0.00** | ||
| (0.00) | (0.00) | |||
| Ingreso per cap (log) | 0.24*** | |||
| (0.03) | ||||
| R2 | 0.18 | 0.19 | 0.19 | |
| Adj. R2 | 0.18 | 0.18 | 0.18 | |
| Num. obs. | 3460 | 3460 | 3305 | |
| RMSE | 1.48 | 1.47 | 1.48 | |
| p < 0.001, p < 0.01, p < 0.05 | ||||
Interpretación: Vemos que el coeficiente de lningreso es de 0.24, sin embargo, debido a que la unidad de medida es logarítmica decimos que por una unidad de porcentaje (1%) de incremento en los ingresos per cápita del hogar, el promedio del índice de participación política aumenta en 0.24/100 = 0.0024, manteniendo todas las demás variables constantes. El coeficiente es estadísticamente significativo a uno 99.9% de confianza. En este caso particular, no es muy informativo, pero corresponde a una manera de especificar un modelo con los ingresos como una variable logaritmizada para hacernos cargo de posible problemas de linealidad.
Debemos tener cautela al interpretar el ajuste del Modelo 5 y 6 debido a que las observaciones empleadas no son las mismas (3462 comparado con 3304) debido a que en el Modelo 5 se incluye la variable ingresos en quintiles con la categoría adicional para los casos perdidos. En este caso, realizamos la especificación a modo de ejemplo. Por lo tanto, seguiremos trabajando con el Modelo 5 para realizar los análisis posteriores.
Test homogeneidad de varianza
## Non-constant Variance Score Test
## Variance formula: ~ fitted.values
## Chisquare = 521.5278, Df = 1, p = < 2.22e-16##
## studentized Breusch-Pagan test
##
## data: fit05
## BP = 385.59, df = 11, p-value < 2.2e-16Tanto el test Breush-Pagan como el de Cook-Weisberg nos indican que existen problemas con respecto a homogeneidad en la distribución de los residuos del modelo debido a que \(p>0.05\) en ambos casos. Es decir, se rechaza \(H_0\) donde se asume que la varianza del error es constante, lo cual nos indica que tenemos problemas de heterocedasticidad en los residuos.
Para hacer frente a este problema, debemos calcular los errores estándar robustos para nuestra última estimación para corregir problemas de heterocedasticidad y así estimar el último modelo nuevamente:
Comparemos los resultados:
labs04 <- c("Intercepto","Sexo (mujer=1)","Edad",
"Quintil 2","Quintil 3","Quintil 4","Quintil 5","Quintil perdido",
"Izquierda (ref. derecha)","Centro","Idep./Ninguno", "Edad²")
htmlreg(list(fit04, fit05, model_robust), doctype = FALSE,
custom.model.names = c("Modelo 4","Modelo 5", "M5 Robust"), custom.coef.names = labs04)| Modelo 4 | Modelo 5 | M5 Robust | ||
|---|---|---|---|---|
| Intercepto | 7.05*** | 7.62*** | 7.62*** | |
| (0.11) | (0.24) | (0.27) | ||
| Sexo (mujer=1) | 0.07 | 0.08 | 0.08 | |
| (0.05) | (0.05) | (0.05) | ||
| Edad | -0.03*** | -0.06*** | -0.06*** | |
| (0.00) | (0.01) | (0.01) | ||
| Quintil 2 | 0.11 | 0.11 | 0.11 | |
| (0.08) | (0.08) | (0.07) | ||
| Quintil 3 | 0.34*** | 0.34*** | 0.34*** | |
| (0.08) | (0.08) | (0.08) | ||
| Quintil 4 | 0.32*** | 0.32*** | 0.32*** | |
| (0.08) | (0.08) | (0.08) | ||
| Quintil 5 | 0.57*** | 0.57*** | 0.57*** | |
| (0.08) | (0.08) | (0.09) | ||
| Quintil perdido | 0.31* | 0.31* | 0.31** | |
| (0.13) | (0.13) | (0.12) | ||
| Izquierda (ref. derecha) | -0.65*** | -0.65*** | -0.65*** | |
| (0.07) | (0.07) | (0.09) | ||
| Centro | -0.71*** | -0.70*** | -0.70*** | |
| (0.08) | (0.08) | (0.09) | ||
| Idep./Ninguno | -1.14*** | -1.13*** | -1.13*** | |
| (0.07) | (0.07) | (0.08) | ||
| Edad² | 0.00** | 0.00** | ||
| (0.00) | (0.00) | |||
| R2 | 0.18 | 0.19 | ||
| Adj. R2 | 0.18 | 0.18 | ||
| Num. obs. | 3460 | 3460 | ||
| RMSE | 1.48 | 1.47 | ||
| p < 0.001, p < 0.01, p < 0.05 | ||||
Los resultados del modelo con errores estándar robustos, nos indica que nuestras estimaciones son robustas a la presencia de heterocedasticidad en los residuos debido a que la significancia de los coeficientes se mantiene si lo comparamos con Modelo 4.
Multicolinealidad
## GVIF Df GVIF^(1/(2*Df))
## sexo 1.057775 1 1.028482
## edad 1.012463 1 1.006212
## quintilemiss 1.085365 5 1.008225
## pospol 1.041316 3 1.006770
## GVIF Df GVIF^(1/(2*Df))
## sexo 1.058907 1 1.029032
## edad 38.308809 1 6.189411
## edad2 38.275011 1 6.186680
## quintilemiss 1.087725 5 1.008444
## pospol 1.042085 3 1.006894Entonces, asumiendo que valores del VIF mayores a 2.5, vemos que en el modelo que no incorpora el término cuadrático de edad no tendríamos problemas de multicolinealidad. Sin embargo, al incorporar el término cuadrático, nos muestra un VIF de 6.2 en la variable edad y edad2.
Reporte de progreso
Contestar aquí.